
The One-Person Project

The first warning sign did not look like a strategy problem. It looked like a QA queue.
Last year, we started changing our QA process. Not because QA mattered less. The opposite. QA started to matter more because AI-assisted development had changed the clock speed of the team.
The old process was familiar: BA clarifies the requirement, design shapes the solution, developers implement it, QA tests it, UAT validates it, and then the team deploys. That process was not wrong. It was built for a world where execution was expensive. Writing code was slow. Changing code was slow. Understanding a system was slow. So the organization split the work across roles and used handoffs to distribute cost and risk.
AI changed the cost structure.
Now a developer working with AI can often run several of those steps inside one loop. The same person can ask the AI to restate the user need, compare solution options, find edge cases, implement the change, write tests, draft documentation, explain the diff, and prepare a first-pass review summary.
That sounds like a productivity story. In practice, it quickly becomes a collaboration problem.
Code, tests, documents, and proposals get produced faster. Review, risk judgment, product context, and system understanding do not speed up at the same rate. QA is asked to validate more change with less shared context. Reviewers are asked to read bigger diffs from people who used AI to move faster than the team could follow. The knowledge gap does not shrink. It can grow.
This is why I keep coming back to a phrase that sounds almost too small for the moment: the one-person project.
I do not mean one person working alone. I do not mean removing QA, weakening review, or turning software teams into a collection of solo operators. I mean a different unit of collaboration: one accountable owner holds the full context of a bounded project or module, uses AI to execute across requirements, implementation, testing, documentation, and iteration, while the team owns the boundaries, interfaces, standards, evidence, and integration points.
AI does not make teamwork disappear. It changes where teamwork has to happen.
The One-Person Project: How AI Coding Changes Software Teams

The old process solved the old bottleneck
The assembly-line software process made sense when the scarce resource was execution.
If code was slow to write and slow to change, then splitting responsibility across BA, design, engineering, QA, UAT, and release management helped. Each role absorbed part of the complexity. Each handoff gave the team a chance to reduce risk. The process was expensive, but the cost was acceptable because the alternative was worse.
AI makes that bargain weaker.
When implementation becomes cheaper, the handoff cost becomes more visible. Every handoff requires someone to rebuild context. Every role sees only part of the intent. Every delay adds distance between the original user problem and the final change. In the pre-AI process, that distance was part of the price of coordination. In an AI-assisted process, that distance can become the main tax.
The uncomfortable part is that AI improves the easiest-to-measure part of the system first: output. It gives us more code, more tests, more summaries, more options, more review comments, more artifacts. But the team still has to decide what matters, what is safe, what should be shipped, and what should be stopped.
That is the new pressure point. AI compresses work. It does not compress responsibility.
Generation is not accountability
The direction of the major tools is already clear.
GitHub Copilot coding agent can take an issue, work in a background environment, create a pull request, leave logs, and wait for human review. OpenAI Codex cloud follows a similar shape: read code, edit code, run code, and create pull requests. Codex code review uses repository guidance from files like AGENTS.md and focuses on higher-priority risks. Claude Code Review analyzes pull requests, but it does not approve or block them.
That product design is important. The agents do more work, but the approval structure remains human.
AI can open a PR. A human accepts the risk. AI can draft tests. A human decides whether those tests are evidence. AI can explain a diff. A human decides whether the explanation is true enough. AI can follow repository instructions. The team has to write those instructions.
The developer role changes because of this. In the old flow, a developer was often one execution role inside a chain. The requirement had been shaped upstream. QA would catch many problems downstream. The developer still carried real responsibility, but part of the cognitive load was distributed across the process.
With AI, more of that work collapses around the developer. The person closest to the code now has enough tool power to clarify the requirement, test assumptions, implement the solution, write the tests, and prepare release evidence. That person becomes closer to a small project owner.
This is not a title upgrade. It is a responsibility radius change.
Review bandwidth becomes the constraint
The obvious benefit of AI coding is speed. It can produce hundreds of lines of code, multiple test files, a design note, a migration plan, and a review summary in minutes.
Human review speed did not increase by the same factor.
That mismatch creates the failure mode I am most worried about: every developer generates more, every reviewer reviews more, and the team calls the result productivity. For a short time, it feels like progress. Then PRs get larger. Context gets thinner. Review comments become more superficial. People approve things because they look plausible and because everyone is busy.
The bottleneck moves from "we cannot build fast enough" to "we cannot understand change fast enough."
DORA's research is useful because it names this as a system problem rather than a mood. The 2024 DORA report found that AI adoption was associated with higher individual productivity, flow, and job satisfaction, while also correlating with weaker delivery throughput and stability. DORA's later generative AI report made the mechanism more concrete: faster code generation can increase batch size, and larger batches are harder to review and more likely to destabilize systems. The 2025 DORA report shows AI adoption becoming near-universal and the throughput relationship improving, but stability remains the downstream weakness.
The practical lesson is not "AI is bad for delivery." The lesson is sharper: AI amplifies the system it enters. A team with strong feedback loops, clear ownership, and good evidence can get faster. A team with weak boundaries and overloaded reviewers can generate more work than it can safely absorb.
The community is saying the same thing in rougher language. In a Hacker News discussion about a code review tool, founders described PR backlogs growing as coding agents produce larger and harder-to-understand pull requests. On Reddit's ExperiencedDevs, engineers are asking how to prevent architectural drift when AI-assisted output rises but review capacity does not grow linearly.
That last phrase is the issue: review capacity does not grow linearly.
If the team response is simply "let everyone generate more code," the review system will become the overloaded gate. If the response is "slow everyone down with the old process," the team throws away the real advantage of AI. The harder answer is to redesign the unit of ownership.
Why one owner starts to make sense
If context is the scarce resource, then keeping context with one owner becomes valuable.
That is the useful version of the one-person project. A bounded project or module should have one person who owns the complete loop: user intent, system constraints, implementation plan, test strategy, release risk, and iteration. Other people still contribute. The team still reviews important boundaries. But the work does not move through a long chain where every role has to rediscover the same intent.
AI extends that owner's execution radius.

Before AI, a strong owner could still get slowed down by mechanical work: boilerplate, test scaffolding, call-stack investigation, release notes, QA checklists, migration notes, design comparison, documentation cleanup. Now AI can help with all of that. The owner's job shifts from doing every step manually to designing the loop and judging the evidence.
This is why Shopify's AI practice is worth studying. First Round's profile of Shopify's AI adoption describes broad access to AI tools, a strong expectation of reflexive AI usage, and AI-native behavior showing up in performance conversations. The more interesting point is not the mandate. It is the process view. Shopify engineering leader Farhan Thawar describes AI's hidden value as helping teams discover that a process should happen in a different order or under different assumptions. He calls it process power.
Shopify's open-source Roast shows the same instinct in tool form. It does not let AI wander through a large codebase without structure. It breaks complex AI workflows into discrete steps and combines nondeterministic AI behavior with deterministic code execution, commands, and checks. The principle is plain: agents need structure because nondeterminism is the enemy of reliability.
That is also the principle behind the one-person project. The point is not that one person can prompt an agent to do everything. The point is that one owner can turn messy work into observable loops. AI accelerates those loops. The owner keeps them pointed at the real goal.
This can fail badly
The phrase "one-person project" has a bad version, and it is worth naming clearly.
The bad version says: AI is powerful, so let a fast individual run with minimal friction. Reduce QA. Reduce review. Treat process as the enemy. Optimize for visible speed.
That can work locally for a while. It also creates predictable damage. Duplicated code increases. API meanings drift. Security and permission boundaries get bypassed. Tests cover the happy path because the AI generated the easiest tests to write. Business rules get scattered across prompts, temporary decisions, and half-reviewed code.
The warning signs are already visible. The 2025 Stack Overflow Developer Survey shows that developers remain cautious about the accuracy of AI tools. GitClear's 2025 AI code quality research points to more duplicated code, more short-term churn, and less moved or reused code in AI-assisted work. You do not have to treat every number as final to take the signal seriously: AI makes code more abundant. It does not automatically make code better.
So the one-person project only works if team boundaries become stronger.
The team still owns architecture direction, cross-module interfaces, security requirements, privacy constraints, observability, release policy, incident learning, and product priorities. Those shared constraints matter more as AI gets faster. Without boundaries, owner speed becomes system risk.
This is the part that feels counterintuitive. AI weakens some forms of collaboration, especially slow role-by-role handoff. At the same time, it raises the value of real team alignment. The old process kept alignment alive through meetings, tickets, QA gates, and review comments. The new process needs more alignment embedded in the system: repository instructions, architecture decision records, design conventions, test contracts, risk scoring, CI gates, feature flags, rollback paths, and production metrics.
The team is no longer mainly an assembly line. It becomes an alignment system.
QA becomes risk and evidence design
QA is the clearest example.
QA does not disappear in an AI-assisted process. But QA as a late manual gate will become more painful. AI-assisted development can produce more changes than a QA team can manually absorb, and the later QA enters the process, the more context QA must reconstruct.
The better direction is for QA to become a risk and evidence discipline.
That means QA helps define acceptance criteria earlier. QA identifies high-risk paths before implementation. QA turns test strategy into evidence that can be generated, executed, reviewed, and traced. AI can draft tests from requirements and historical bugs. AI can run a first-pass PR risk scan. Human QA can focus on business-critical paths, integration points, abnormal flows, permission boundaries, and user experience. Production monitoring, feature flags, gradual rollout, rollback, and postmortems complete the quality loop.
This does not reduce QA's value. It increases QA's leverage.
Traditional QA is often forced to repay process debt at the end. In an AI era, that debt grows faster. Effective QA should define what evidence would make the team confident enough to ship, and what risk should stop the work before it gets expensive.
That also changes the developer's job. A project owner cannot assume "QA will look at it later." The owner should use AI to produce evidence first: tests, logs, screenshots, diff summaries, risk notes, migration plans, rollback paths. Then QA and reviewers are not starting from a pile of AI-generated output. They are reviewing a case.
The model: owner, agents, boundary, evidence
The most practical frame I have found is four words: owner, agents, boundary, evidence.
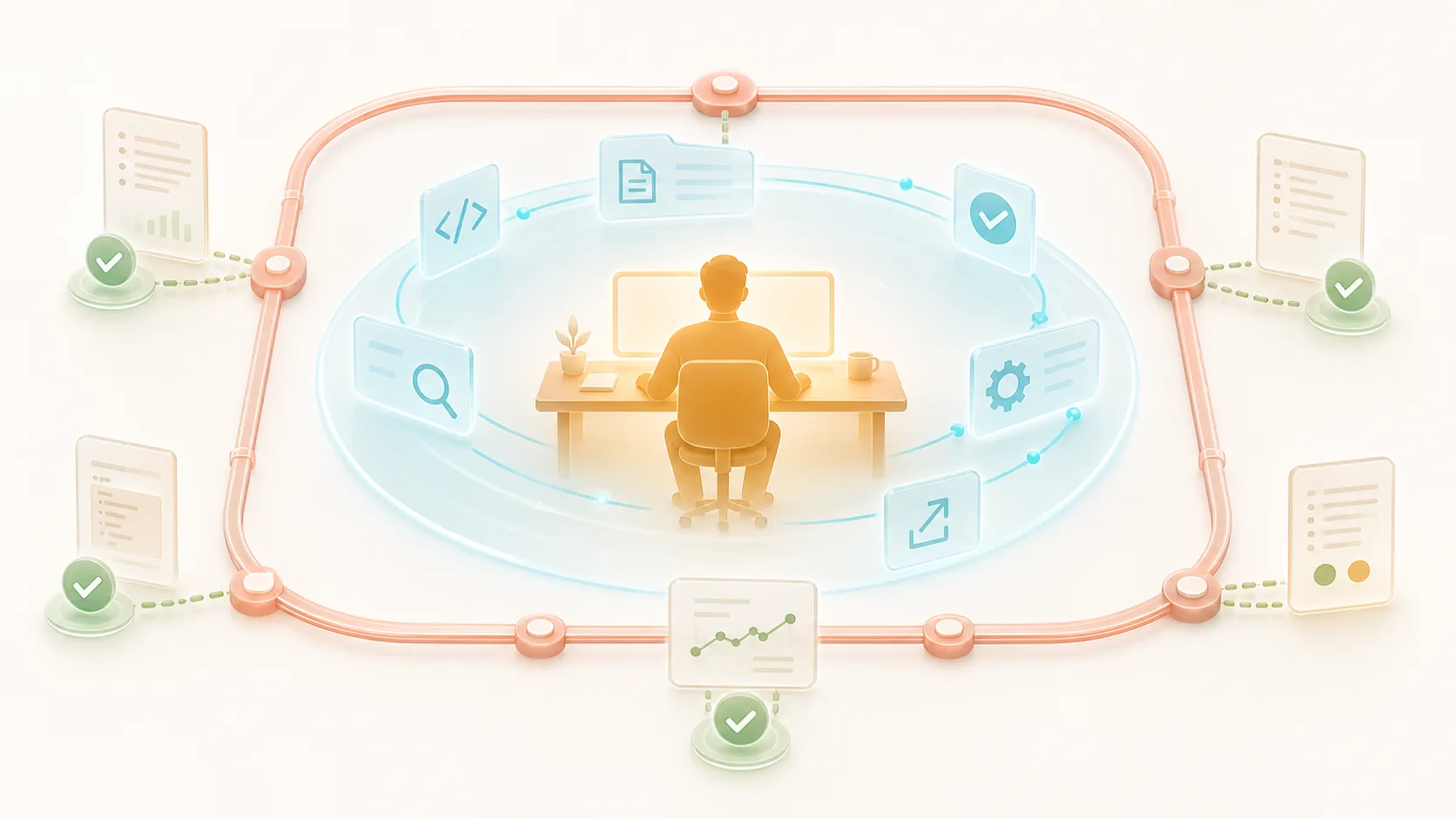
Owner is the accountable human who holds continuous context. The owner is not the only person writing code or making every decision, but the owner understands the goal, constraints, risks, and result. Without an owner, AI output drifts.
Agents are execution radius. They help with requirement breakdown, solution comparison, implementation, testing, documentation, review, debugging, migration, and cleanup. Agents own tasks. They do not own responsibility.
Boundary is the shared constraint system the team provides: architecture boundaries, API contracts, design rules, security policies, repo instructions, module ownership, feature flag policy, release policy. Boundary lets individuals move quickly without damaging the broader system.
Evidence is what makes speed trustworthy: test results, CI, coverage, screenshots, logs, traces, benchmarks, review notes, risk checklists, and production metrics. The more AI output grows, the more evidence matters, because humans cannot manually reconstruct every detail.
This model changes the shape of collaboration.
The old model was sequential: one role finishes, then hands off to the next role.
The AI-era model is more loop-based: one owner moves quickly with agents inside shared boundaries and continuously produces evidence. The team intervenes at important risks, boundaries, and integration points.
Not every change should carry the same process weight. Low-risk changes with strong evidence can move quickly. Cross-boundary changes, permission changes, migrations, and architectural shifts need heavier review. AI-generated tests can improve coverage, but they cannot replace test strategy. AI review can be a useful first pass, but it cannot replace accountable human review.
That is what I mean by the one-person project: one person owns the complete loop, while the team owns the boundary.
The real organizational change
Software teams used to look like assembly lines because execution was expensive. Each role owned a stage, and handoff made complexity manageable.
Once AI lowers execution cost, the hidden cost of that structure becomes harder to ignore. Every handoff loses context. Every wait slows iteration. Every role that only sees its slice struggles to understand the intent behind a growing volume of AI-generated change.
The division of labor that once improved efficiency can become the communication cost that limits it.
The deeper change is not headcount. It is accountability architecture.
The old organization design broke complex responsibility across roles, then used process to stitch the pieces back together. In the AI era, that stitching becomes more expensive because execution is no longer the scarcest resource. Context and judgment are. When a requirement keeps moving across BA, design, development, QA, UAT, and release, every move requires someone to explain intent again, rebuild the mental model, and re-evaluate risk. AI makes each role faster at producing output. It does not make those re-explanations free.
The one-person project is responsibility recombining.
One owner holds product intent, technical context, quality evidence, and release risk together. AI expands that owner's execution radius. The team turns boundaries, interfaces, standards, and auditability into a shared system. A good team does not need to interrupt the owner constantly to feel safe. It makes the owner's work visible, verifiable, and reversible by design.
This is why AI-era management is more subtle than "use more AI." That instruction mostly creates more output. It is also more subtle than forcing AI speed back into the old workflow. That wastes the advantage. The useful management question is about the grain of responsibility: which work should have one end-to-end owner, which work must enter team review, what evidence is enough for a fast merge, and which boundaries require an immediate pause.
My current answer is: single owner, shared boundary.
The operating rule is simple: give one person the whole loop, give the team the boundary, and make every important decision leave evidence. Without an owner, AI output drifts. Without a boundary, owner speed becomes system risk. Without evidence, trust collapses into opinion.
That is not the decline of teamwork. It is teamwork moving to a higher level of abstraction.
In the assembly-line era, the team's value was organizing many people into a production process. In the AI era, the team's value is letting a high-ownership person safely carry more responsibility with AI. The first model optimized labor division. The second optimizes judgment, boundary, and trust.
The strongest software teams will stop asking only, "What does each role do in this process?"
They will ask a sharper set of questions:
Who owns this end to end? Which agents can they use? Where are the team boundaries? What evidence would make us trust this enough to ship?
The teams that can answer those questions will keep individual speed without losing team quality.